Paper Reading: Towards Data-Efficient Detection Transformers
Background
Detection transformers (like DETR) are data-hungry, the performance of detection transformers drops significantly on small training dataset.
Related Work
Detection transformers:
- DETR: Basic end to end solution
- Deformable DETR, CondDETR : Concern on alleviating the slow convergence problem of DETR
- The frameworks follow the label assignment approach of DETR
Data-Efficiency of VIT:
- DeiT: knowledge distillation from pre-trained CNNs ……
Method
Difference Analysis of RCNNs and DETRs(Analysis)
Transform Sparse RCNN to DETR by replacing/adding/removing the components (Ablation experiment). The details are in 3.2.
—> 3 key factors:
(a) sparse feature sampling from local regions, e.g., using RoIAlign
(b) multi-scale features which depend on sparse feature sampling to be compu-tationally feasible
(c) prediction relative to initial spatial priors
(a) and (c) help the model to focus on local object regions and alleviate the re-quirement of learning locality from a large amount of data, while (b) facilitates a more comprehensive utilization and enhancement of the image features, though it also relies on sparse features. —-> local features are important to data-efficiency
Improve Data-efficiency
- Sample the local features under the guidance of the former decoder layer.
- concatenated to the high-resolution features extracted by the backbone. (Multi-scale features)
The above 2 methods are peroformed on key and value sent to decoder - Label Augmentation: repeat the labels of each foreground —> enhance positive supervision signal
Evaluation/Experments
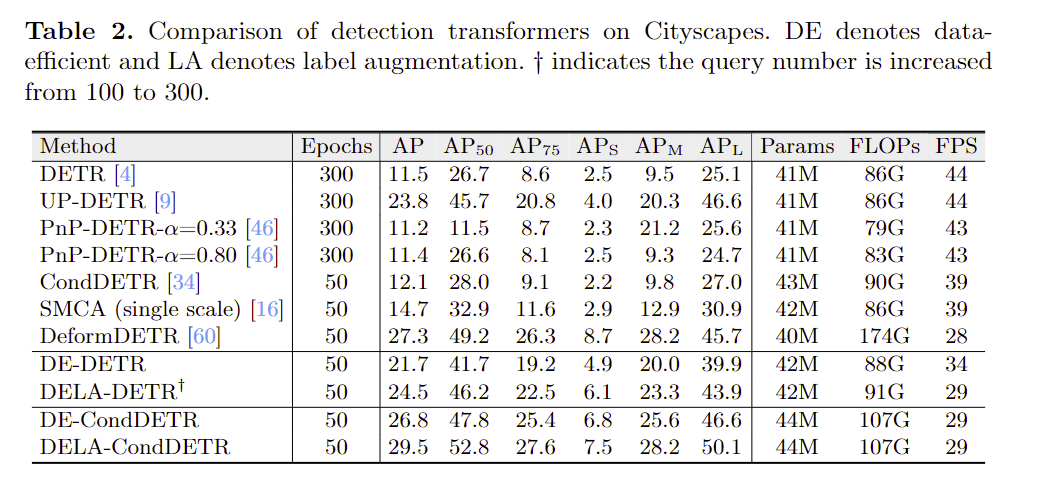
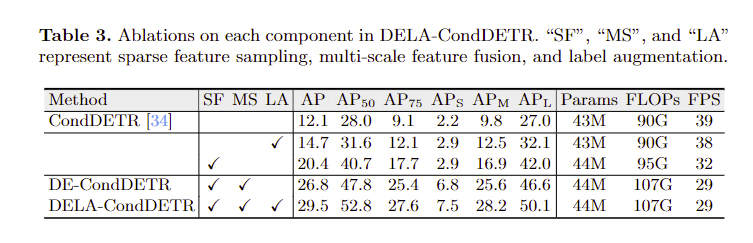
Reading Summary
What is the contribution/novelty?
- Proved that local features are important to data-efficiency
- proposed sparse feature sampling and incorporated multi-scale feature to improve data-efficiency
- Label augmation strategy
What is the existing issue?
Deformable DETR has better $AP_S$ in Table 2. but a lower $AP_L$ comparing to DELA-CondDETR, although they both concern on the local ans sparse features. How can we combine the pros of the two methods (by improve the attention module and decoder key/value generation, can be inspired from YSLAO?)? (Although it is not the focus of this paper).