Paper Reading: You Should Look at All Objects
Background
Feature Pyramid Network Leads to a higher performance in detecting small-scale objects but a lower performance in detecting large-scale objects (i.e. higher $AP_S$ and lower $AP_L$)
assumptions on why FPN works?
- assumption 1: FPN helps obtain better representations by fusing multiple low-level and high-level feature maps
- assumption 2: Different level detect the objects in a certain scale range
The 2 assumptions hould lead to the same conclusion that the increase in AP is due to the co-increase in $AP_S$, $AP_M$ and $AP_L$. ——> There are other key differences between FPN-free and FPN-based detection frameworks
Related Work
FPN: 3 types
- top-down or bottom-up networks: like PANet
- attention based methods: like SAFNet
- neural architecture search based approaches: like Nas-fpn
The researchs are based on the above assumptions, and cannot explain why introducing FPN will suppress the performance of large-scale objects.
Method
Revisit FPN:
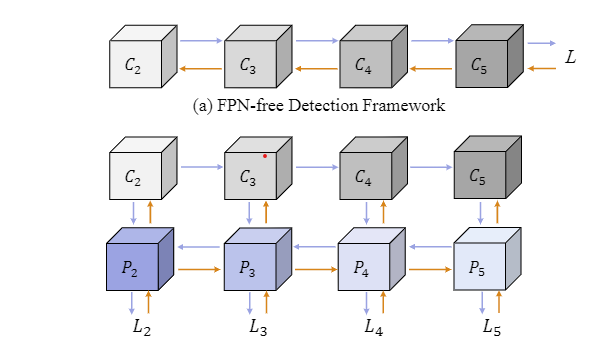
Found the back-propagation paths between FPN-free detection framework and FPN-based detection framework is different. The blue arrows represent for forward and the orange arrows denote for back propagation
Analysis:
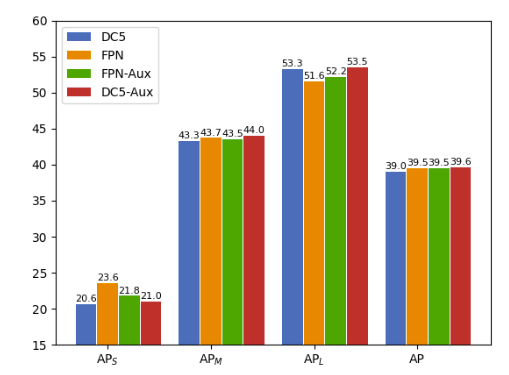
Why FPN works
Assumption: FPN avoid vanishing gradient problem in shallow layers of backbone in FPN-free Detection Framework
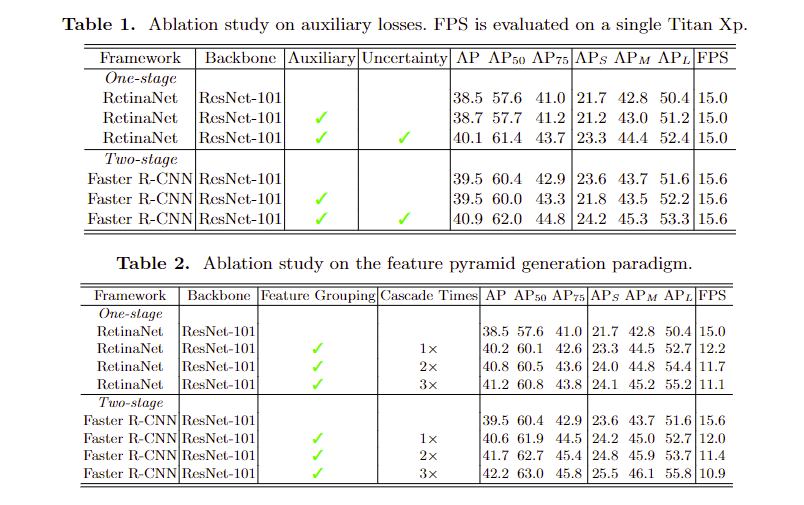
—> add auxiliary losses in the shallow layers of the backbone to demonstrate it
auxiliary loss(two-stage detector has other form, see Eq.(9))
—> auxiliary losses improves performance of FPN-free Detection Framework but have no effect on FPN-based Detection Framework —> Conclusion: the nature of the success of FPN is the shorten back-propagation distance between the objective losses and the shallow layers of the backbone network.
Why FPN suppresses the detection performance of large-scale object
Assumption: $P_2$ is used to detect small objects, while $P_5$ is used to detect large objects. $L_2$ constrains $C_2$ to focus on small objects, $C_2$ is used to extract semantic features of the larger objects by $f_{s2}$ in forward-propagation, which is insufficient. The adverse effects will be further accumulated when leveraging $f_{s3}$ and $f_{s4}$ to calculate $C_4$ and $C_5$. —> The above auxiliary loss experment also validates the assumption.
Proposed improvement
Auxiliary loss
Incorporate the uncertainty into each classification and regression auxiliary loss (Eq.(10)), uncertainty is calculated by $\alpha=ReLU(w \cdot x + b)$, x is feature map, w, b is learnable parameters.
new FPN Paradigm: Feature Grouping && Cascade Structure
motivation: the summation of $L_l$ can make each backbone level own the ability to look at all objects
Step:
- feature grouping: use $C_l’$ and $M_k$ (see Fig.4) to do $X_k$, split $X_k$, combine the part of $X_k$ from each level, generate feature pyramid $P_l$
- Cascade Structure: generate a $P_l’’$ by (Eq.(17)) before contruct feature pyramid $P_l$, use $P_l’’$ to replace the $P_l’$ in (Eq.(16)) to construct feature pyramid $P_l$. (to fuse the $X_{k, l}$)
My thoughts: guess about the function of $M_k$ in (Eq.(12)) : A linear transformation (learnable), combine/remove/transorm the feature map along the channel dimension (1-dimension), when $X_k$ is divided into quarters along the channel dimension, each divided part could get enough/needed features. $M_k$ fuses the features of each layer, and the generated $X_k$ is divided and each part is used to construct the feature pyramid for different level.
Each $P_l$ uses information from different pyramid level, i.e. : $P_l’=X_{2,l}\oplus X_{3,l}\oplus X_{4,l}\oplus X_{5,l}$ ($\oplus$ is concatenation) uses part of imformation from $X_k$ of level 2~5
Evaluation/Experments
Reading Summary
What is the contribution/novelty?
- Analyzed the mechanism of FPN and explained why introducing FPN will suppress the performance of large-scale objects.
- Proposed 2 methods to improve the performance of FPN-based detection franework on large-scale objects
- Auxiliary loss build extra back-propagation paths between the objective functions and the backbone levels —-> increase $AP_L$, but decrease $AP_S$
- Feature Grouping amends the back-propagation paths between objective functions and the backbone network
- Cascade Structure enhances the space compactness of the homogeneous feature maps
- The methods are generic, which could be used in various detection frameworks, even other vision tasks (like instance segmentation)
What is the existing issue?
Fig.4 may lack some details(AdaptiveAvgPool and parameters of $1 \times 1$ Conv)
Future work?
Can we use something that uses multi-head self-attention mechanism to generate $M_k$?(compute complexity could be a problem even it is patched)