Self-Consuming Generative Models Go MAD
Background
- training datasets tend to be sourced from Internet —> Models are unwittingly being trained on increasing amounts of AI-synthesized data
- use of synthetic data to train generative models —> forms an autophagous (“self-consuming”) loop
Defined 3 types of training loops:
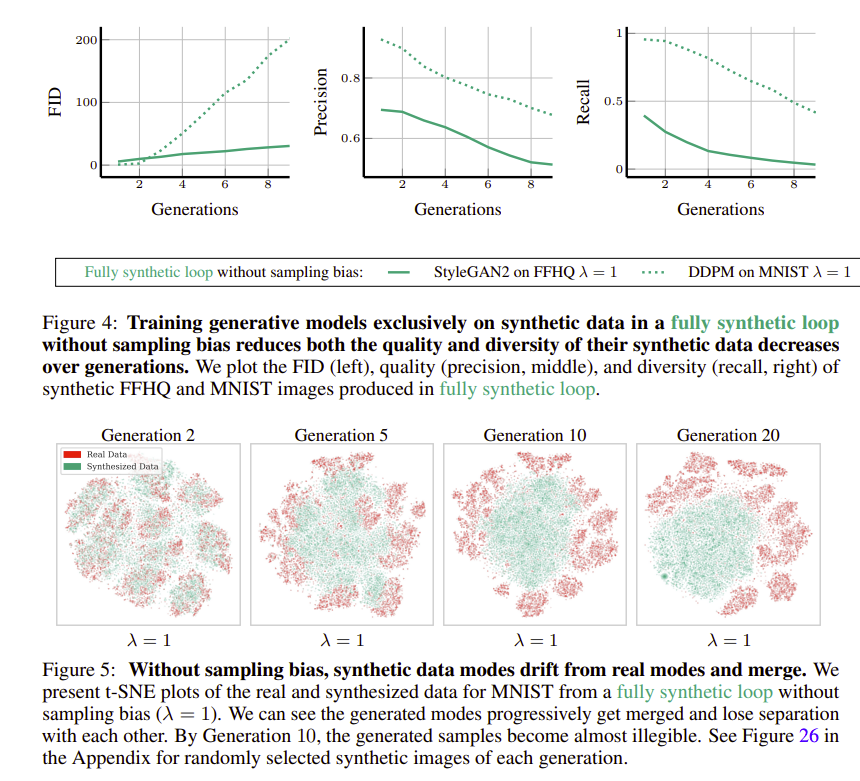
- fully synthetic loop: the training dataset for each generation’s model consists solely of synthetic data sampled from previous generations’ models
- synthetic augmentation loop: the training dataset for each generation’s model consists of a combination of synthetic data sampled from previous generations’ models plus a fixed set of real training data
- fresh data loop: the training dataset for each generation’s model consists of a combination of synthetic data sampled from previous generations’ models plus a fresh set of real training data
Sampling bias:
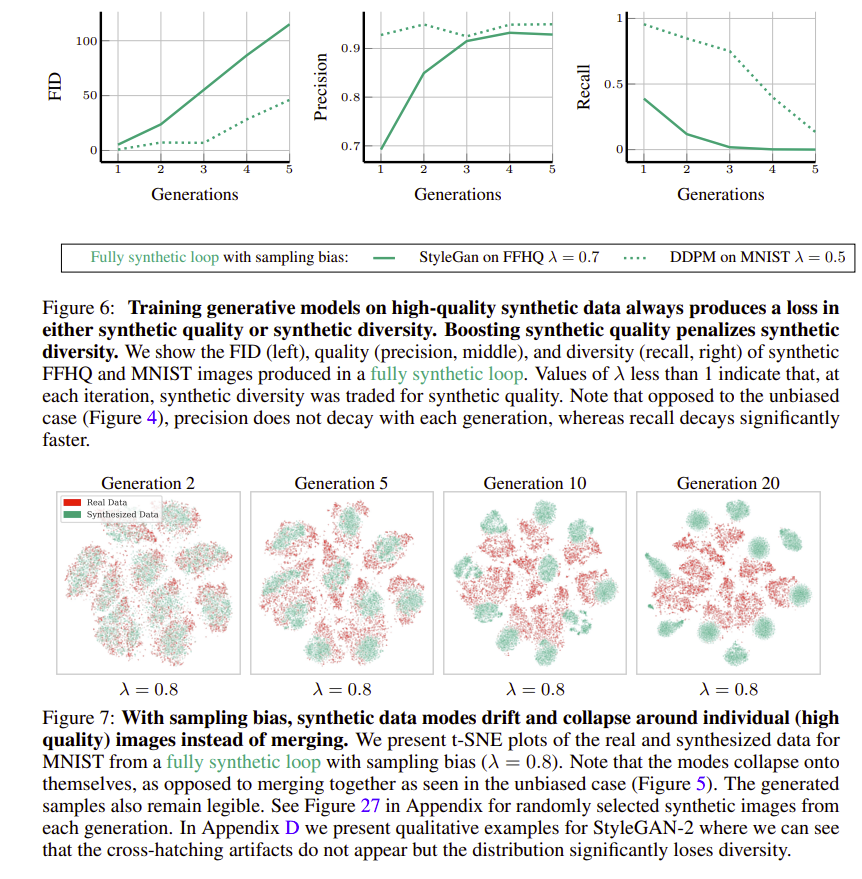
Users of generative models tend to manually curate (“cherry-pick”) their synthetic data. Without sampling bias, autophagy can lead to a rapid decline of both quality and diversity, whereas, with sampling bias, quality can be maintained but diversity degrades even more rapidly.
Related works:
VAE, LLMs … sampling bias can prevent a drop in image quality in diffusion model trained with fully synthetic loop.
The performance of DDIM without samling bias trained with synthetic augmentation loop will drop over generations.
Methods
Autophagous processes
Define: A MAD generative process is a sequence of distributions $(\mathcal{G}^t)_{t \in N}$ that follows the distance metric on distributions between the generative model $\mathcal{G}^t$ and the reference probability distribution $\mathcal{P}_r$ increases with $t$.
drive an autophagous process MAD:
- The balance of real and synthetic data in the training set (i.e. Variants of autophagous processes)
- the manner in which synthetic data is sampled from the generative models (i.e. Biased sampling in autophagous loops)
Variants of autophagous processes
$\mathcal{D}_r^t$ are real data samples, $\mathcal{D}_s^t$ are synthetic data samples, $\mathcal{D}^t=(\mathcal{D}_r^t, \mathcal{D}_s^t)$, add detailed for the 3 training loops.
- fully synthetic loop: when $t>=2$, $\mathcal{G}^t$ trained on the synthetic data sampled from models $(\mathcal{G}^t)_{\tau =1}^{t-1}$ . i.e. $\mathcal{D}^t=\mathcal{D}_s^t(t>=2)$
- synthetic augmentation loop: when $t>=2$, $\mathcal{D}^t=(\mathcal{D}_r, \mathcal{D}_s^t)$, the real training set $\mathcal{D}_r$ is fixed
- fresh data loop: when $t>=2$, $\mathcal{D}^t=(\mathcal{D}_r^t, \mathcal{D}_s^t)$, where $\mathcal{D}_r^t$ is sampled independently from $\mathcal{P}_r$.
Biased sampling in autophagous loops:
cherry-picking the synthetic samples via the biased sampling methods that are commonly used in generative modeling practice.
Define a universal sampling bias parameter $\lambda$ to express the parameters used to control sample quality uniformly:
- $\lambda = 1$ corresponds to unbiased sampling, $\lambda = 0$ corresponds to sampling from the modes of the generative distribution $\mathcal{G}^t$ with zero variance
- in general synthetic sample quality will increase and diversity decrease as $\lambda$ is decreased from 1
- For DDPM: define $\lambda = \frac{1}{1+w}$, where $w$ is guidance factor of classifier-free diffusion guidance.
The fully synthetic loop
For $\mathcal{G}^t=mathcal{N}(\mu_t, \sum_t)$, the $\mu_t, \sum_t$ are martingale and supermartingale processes, respectively, Moreever the $\sum_t$ is a bounded supermartingale processes, the covariance $\sum_t$ is guaranteed to converge to zero. Which means when we sample data from that distribution repeatedly, not only should we expect some modal drift because of the random walk in $\mu_t$ (reduction in quality), but we will also inevitably experience a collapse of the variance (vanishing of diversity).
The magnitudes of the steps of the random walk in $\mu_t$ are determined by two main factors: the number of samples ns and the covariance $\sum_t$ (because $\mu_t \sim \mathcal{N}(\mu_{t-1}, \frac{\lambda}{n_s}\sum_{t-1})$), the smaller the choice of $\lambda$ the more rapidly $\sum_t$ will converge to zero, stopping the random walk of $\mu_t$. Thus, the sampling bias factor $\lambda$ provides a trade-off to preserve quality at the expense of diversity.
Without biased sampling
With biased sampling
synthetic augmentation loop
keeping the original real dataset in the synthetic augmentation loop only slows the malignant effects of the fully synthetic loop instead of preventing them.
fresh data loop
- the performance of later generations converges to a point that depends only on the amounts of real and synthetic data in the training loop ($n_r, n_s, \lambda$), and is independent from the Initial model (i.e. independent from $n_{ini}$)
$\lim_{t \to \infty} \mathbb{E} [dist(\mathcal{G}^t,\mathcal{P}_r)]=WD(n_r,n_s,\lambda )$ - while limited amounts of synthetic data can actually improve the distributional estimate in the fresh data loop—since synthetic data effectively transfers previously used real data to subsequent generations and increases the effective dataset size—too much synthetic data can still dramatically decrease the performance of the distributional estimate
- modest amounts of synthetic data actually boost performance, but when synthetic data exceeds some critical threshold, the models suffer
use Monte-Carlo simulation to calculate the limit point of the fresh data loop of the above equation, then compare against an alternative model G(ne) trained only on a collection of real data samples of size $n_e$(also called effective sample size), if $n_e / n_r >= 1$, the synthetic data effectively increases the number of real samples.
For given combination of $n_r$ and $\lambda < 1$, if $n_s$ exceeds some admissible threshold, the effective sample size drops below the fresh data sample size
more sampling bias (smaller $\lambda$) actually reduces the number of synthetic samples that can be used without harming performance (i.e. more sampling bias reduces the threshold of $n_s$) (only tested in Gaussian modeling)
Reading Summary
What is the contribution/novelty?
- Consider 3 types of training loops.
- Build math model for fully synthetic loop, explained why the fully synthetic loop is harmful.
- Figure out the effect of bias sampling in MAD generative process.
- The research is not limited in image generation model.
What is the existing issue / What can be done in the future?
- How to identify synthetic data (current: watermark synthetic data) —> research on autophagy-aware watermarking (Or the synthetic image detection?)
- application of manifolds distance in other tasks